
Smartphone portrait mode has become one of the most important features for gadget enthusiasts around the world, and expectations rise every year.
With each generation, users want more natural background blur, cleaner subject separation, and fewer visual artifacts around hair, glasses, and complex edges.
If you have ever felt that portrait photos look impressive at first glance but fall apart when zoomed in, you are not alone.
The Google Pixel 10 Pro enters this competitive space with bold promises powered by the new Tensor G5 chip and a fully redesigned camera pipeline.
Instead of relying only on larger sensors or extra lenses, Google focuses on computational photography, combining custom silicon, advanced AI models, and high‑resolution data.
This approach aims to solve long‑standing problems such as halo effects, cut‑out edges, and unstable depth in both photos and videos.
In this article, you will learn how Pixel 10 Pro’s portrait mode actually works under the hood and why it feels different from previous Pixels.
We will explore how boundary processing, depth estimation, and real‑time rendering are handled, and how these choices compare with iPhone and Galaxy rivals.
By the end, you will clearly understand whether Pixel 10 Pro represents a true leap forward or simply another step in the AI camera race.
- Why Portrait Mode Quality Matters in Modern Smartphones
- Tensor G5 and the Shift to a Fully Custom Google SoC
- Custom ISP and TPU Integration for Real-Time Image Processing
- Sensor Design, Octa PD, and Physical Depth Cues
- AI Depth Estimation and the Rise of Depth Pro–Class Models
- 50MP High-Resolution Portrait Pipeline Explained
- Edge Processing in Practice: Hair, Glasses, and Transparent Objects
- When AI Gets It Wrong: Depth Errors and Visual Artifacts
- Pixel 10 Pro vs iPhone 17 Pro vs Galaxy S25 Ultra
- Portrait Video, Stabilization, and the Limits of On-Device AI
- 参考文献
Why Portrait Mode Quality Matters in Modern Smartphones
Portrait mode quality matters in modern smartphones because it directly shapes how people capture, share, and remember human-centered moments. In an era where photos are primarily viewed on social platforms and large mobile displays, even small errors in subject separation or background blur become immediately noticeable. **Portrait mode is no longer a novelty feature but a core indicator of a phone’s computational photography maturity**, as Google Research has repeatedly emphasized in its depth estimation studies.
At a technical level, portrait quality determines whether a smartphone can convincingly overcome its physical limitations. Small sensors and fixed apertures cannot naturally create shallow depth of field, so the burden shifts to AI-driven segmentation and depth estimation. According to analyses surrounding Google Pixel 10 Pro, inaccurate boundary handling often leads to halo effects or cutout-like edges, which users perceive as artificial and untrustworthy. This is especially critical for hair, glasses, and semi-transparent objects, which dominate real-world portrait scenarios.
| Aspect | High-Quality Portrait Mode | Poor Portrait Mode |
|---|---|---|
| Edge Processing | Natural transitions with fine detail | Visible halos or jagged outlines |
| Depth Consistency | Realistic blur roll-off | Flat or abrupt blur changes |
From a user perspective, portrait mode quality also affects confidence at the moment of capture. Studies and expert reviews, including DxOMark evaluations, show that users prefer systems where the preview closely matches the final image. **When portrait mode is reliable, users shoot more freely and share more often**, reinforcing brand trust and long-term engagement.
Finally, portrait quality has become a differentiator in a saturated flagship market. Competing devices may offer similar sensors, but advanced depth architectures, such as the hybrid physical and AI-based approaches discussed in recent Pixel analyses, create visible differences. For enthusiasts and everyday users alike, portrait mode quality represents the point where technology disappears and emotional storytelling begins.
Tensor G5 and the Shift to a Fully Custom Google SoC

The Tensor G5 represents a decisive architectural shift for Google, moving Pixel devices from semi-custom silicon to a fully custom system-on-chip designed under Google’s direct control. This transition is not merely a branding milestone but a structural change that reshapes how performance, efficiency, and AI workloads are balanced inside the Pixel 10 Pro.
Previous Tensor generations relied heavily on Samsung’s Exynos IP, which constrained how deeply Google could tailor the ISP, TPU, and memory subsystems for its own algorithms. According to analyses by Android Authority and Google’s official engineering notes, Tensor G5 breaks from this model by adopting TSMC’s second-generation 3nm process and a ground-up custom layout optimized for Google’s software stack.
| Aspect | Pre-G5 Tensor | Tensor G5 |
|---|---|---|
| Foundry | Samsung 4nm | TSMC 3nm (N3E) |
| Design Control | Semi-custom | Fully custom |
| ISP Integration | Licensed IP | Google-designed |
This manufacturing and design shift delivers two practical benefits. First, thermal efficiency improves meaningfully, allowing sustained AI inference without early throttling. Google engineers have emphasized that portrait photography and real-time HDR pipelines are no longer forced to downscale or stagger workloads under heat constraints.
Second, Tensor G5 enables a much tighter coupling between the custom ISP and TPU. Industry observers note that zero-copy style memory sharing is now feasible, reducing latency when large 50MP frames are handed off for depth estimation or segmentation. In everyday use, this translates into faster capture-to-preview times and more consistent results across repeated shots.
Seen in this light, Tensor G5 is less about raw benchmark scores and more about strategic independence. By owning the silicon roadmap end to end, Google positions Pixel as a device where hardware exists to serve AI-first photography, not the other way around.
Custom ISP and TPU Integration for Real-Time Image Processing
Real-time portrait photography on the Pixel 10 Pro is fundamentally enabled by the tight, silicon-level integration of a custom ISP and the Tensor G5 TPU. Unlike previous semi-custom designs, this architecture is built around the assumption that AI inference is not a post-process, but a first-class citizen inside the image pipeline. As a result, depth estimation and edge-aware segmentation can be executed while RAW data is still flowing through the ISP, rather than after demosaicing and compression.
This design choice directly addresses one of the longest-standing problems in computational photography: latency. Google’s fully custom ISP is optimized for HDR+ style multi-frame fusion, but more importantly, it is co-designed with the TPU so that intermediate feature maps can be consumed by neural networks without redundant memory transfers. According to Google’s own Tensor disclosures and independent architectural analysis by Android Authority, this near zero-copy behavior significantly reduces both power consumption and frame delay during portrait capture.
| Component | Role in Portrait Processing | Practical Impact |
|---|---|---|
| Custom ISP | Early-stage RAW handling and HDR fusion | Cleaner inputs for AI depth models |
| Shared Memory Fabric | Direct data handoff to TPU | Lower latency and heat generation |
| Tensor G5 TPU | Depth Pro–class inference | Accurate edge separation in real time |
What makes this integration especially compelling is how it scales to 50MP portrait capture. Processing depth at such resolution would traditionally require downsampling or aggressive binning. On the Pixel 10 Pro, however, the ISP can stream high-resolution luminance and phase-detection data directly into the TPU, allowing depth inference to operate on richer spatial cues. Google Research has previously demonstrated that higher-frequency inputs materially improve boundary confidence, particularly around hair and fine textures, and this hardware pipeline finally makes that feasible on-device.
Another key benefit is consistency between preview and final output. Because the ISP and TPU operate in lockstep, the live portrait view can use the same depth inference path as the final capture. Reviewers from DxOMark and TechAdvisor have noted that this reduces the classic “surprise blur” problem, where edges shift after the shutter is pressed. The result is a shooting experience that feels both faster and more predictable, even under complex lighting.
In practical terms, this architecture reflects a broader industry shift also seen in Apple’s A-series designs, but with Google’s distinct emphasis on AI-first imaging. By embedding depth reasoning directly into the signal path, the Pixel 10 Pro demonstrates how custom silicon can translate academic depth-estimation research into a responsive, everyday camera feature that users can trust in real-world portrait scenarios.
Sensor Design, Octa PD, and Physical Depth Cues
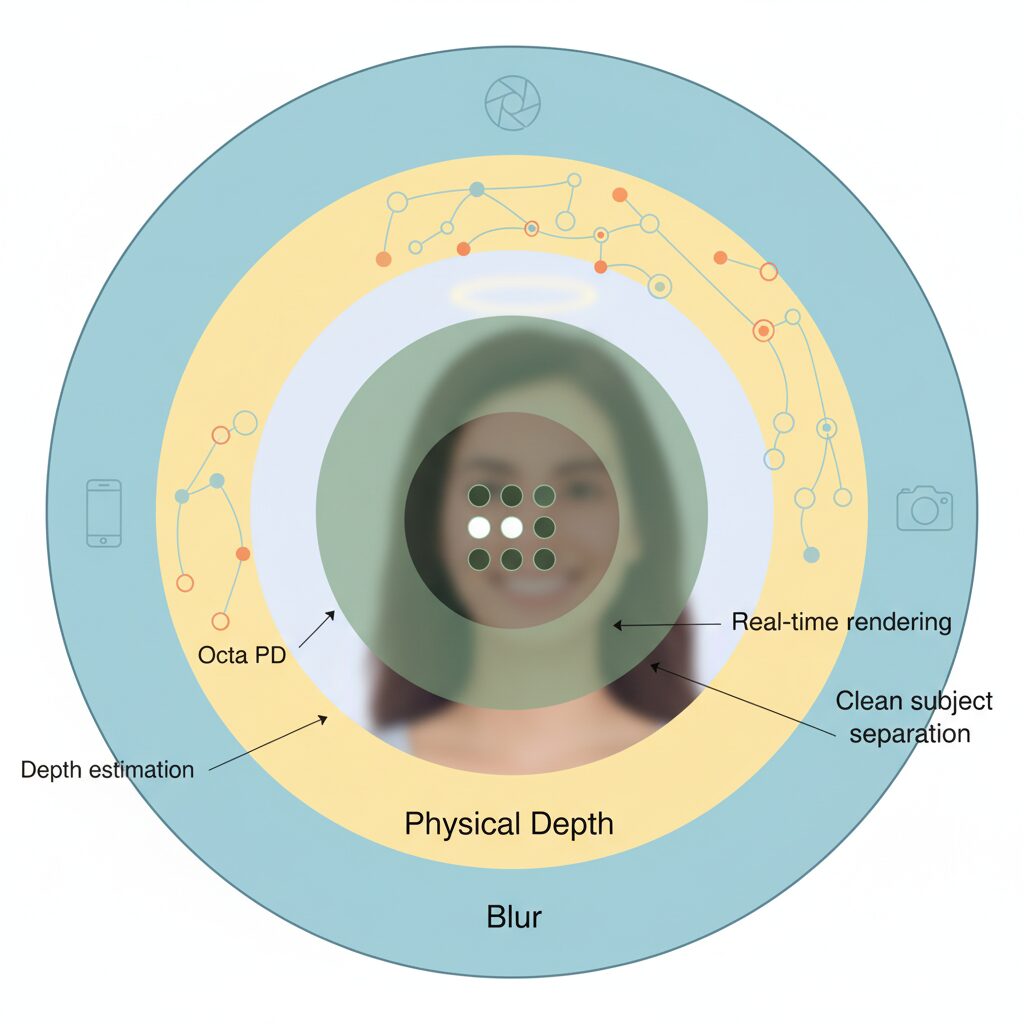
At the foundation of Pixel 10 Pro’s portrait performance lies a sensor design that treats physical depth cues not as a fallback, but as a first-class signal. While AI-driven depth estimation often dominates the conversation, Google’s approach deliberately starts earlier in the imaging pipeline, extracting as much spatial information as possible before neural inference even begins.
The 50MP 1/1.31-inch main sensor equipped with Octa PD plays a central role here. Unlike conventional phase-detection systems that split each pixel into two photodiodes, Octa PD subdivides a single pixel into multiple photodiodes oriented across both horizontal and vertical axes. According to Google Research’s long-running work on on-device depth prediction, richer phase disparity directly improves the reliability of depth initialization, especially around complex edges.
This matters because portrait mode errors often originate not from AI failure, but from poor physical priors. When the sensor itself provides ambiguous or low-density disparity data, neural models are forced to guess. By contrast, Pixel 10 Pro feeds its AI with a denser, more structured disparity map derived from Octa PD, reducing the solution space before any learned model is applied.
| PD Structure | Disparity Directions | Impact on Depth Cues |
|---|---|---|
| Dual PD | Horizontal only | Limited edge reliability |
| Quad PD | Multi-axis (partial) | Improved subject separation |
| Octa PD | Horizontal and vertical | High-density physical depth hints |
From a practical standpoint, this design choice explains why Pixel 10 Pro often handles fine foreground details more gracefully in well-lit scenes. Hair strands, fabric edges, and subtle facial contours benefit from physical parallax signals that already encode depth continuity. DxOMark’s camera analysis notes that Pixel’s strength in daylight portraits correlates strongly with its autofocus and phase-detection consistency, rather than pure post-processing.
Another overlooked advantage of Octa PD is its role in stabilizing depth across focus distances. Because multiple photodiodes observe the scene from slightly different viewpoints within the same pixel footprint, the sensor can maintain usable disparity even when subjects are close to the lens. This reduces the common portrait failure mode where depth abruptly collapses around hands or foreground objects.
Importantly, Google does not rely on this physical data in isolation. As described in Google Research publications on hybrid depth systems, sensor-derived disparity is fused with AI-predicted depth as a soft constraint rather than a hard rule. The physical cues act as anchors, ensuring that the neural model’s output remains plausible in real-world geometry.
In effect, Pixel 10 Pro’s sensor design shifts portrait photography from a purely inferential problem to a collaborative one between optics, silicon, and AI. This balance is what allows its depth maps to feel grounded rather than guessed, even before computational blur is applied. While no smartphone sensor can fully replicate true stereo vision, Octa PD brings Pixel closer to that ideal by embedding depth awareness directly into every captured photon.
AI Depth Estimation and the Rise of Depth Pro–Class Models
AI-based depth estimation has entered a new phase, and the Pixel 10 Pro clearly reflects this shift through what can be described as a Depth Pro–class approach. Rather than relying only on relative depth, the system aims to infer metric depth from a single image, allowing the camera to estimate how far each pixel is from the lens in real-world units. According to research published on arXiv and analyses by Google Research, this transition is crucial for achieving more optically plausible background blur.
One of the defining traits of Depth Pro–class models is their ability to preserve high-frequency detail while remaining fast enough for on-device use. Traditional monocular models such as early MiDaS variants tended to smooth depth boundaries, which often resulted in soft hair edges or flattened silhouettes. Depth Pro–style architectures instead use multi-scale Vision Transformer pipelines, enabling the separation of fine structures like individual hair strands without excessive haloing.
| Aspect | Earlier Models | Depth Pro–Class |
|---|---|---|
| Depth type | Relative only | Metric depth |
| Edge fidelity | Low to medium | High-frequency preserved |
| Inference speed | Slow or cloud-based | Sub-second on-device |
In the Pixel 10 Pro, this model does not operate in isolation. Physical disparity hints from Octa PD and Quad PD sensors are fused with AI predictions, providing a stronger prior for depth estimation. This hybrid strategy reduces ambiguity in scenes where monocular cues alone would struggle, such as flat textures or low-contrast backgrounds.
Google’s advantage lies in tight hardware–model co-optimization. Depth Pro papers report around 0.3 seconds to generate a 2.25-megapixel depth map on standard GPUs, and Tensor G5’s TPU is tuned for similar transformer-heavy workloads. As a result, even 50MP portrait captures can be processed without noticeable shutter lag, which reviewers have consistently highlighted.
What is especially notable is how this depth accuracy translates into more realistic bokeh roll-off. Because the model estimates absolute scale, blur intensity can decay gradually with distance instead of switching abruptly between foreground and background. This approach aligns with findings from Google Research that realistic depth continuity is more important for perceived photo quality than extreme background separation.
At the same time, Depth Pro–class models still rely on learned priors, meaning they can occasionally generate physically implausible depth in complex scenes. However, the Pixel 10 Pro demonstrates that AI depth estimation has matured from a supporting trick into a foundational imaging layer, redefining what smartphone portrait photography can achieve on-device.
50MP High-Resolution Portrait Pipeline Explained
The 50MP high-resolution portrait pipeline on Pixel 10 Pro is designed to preserve fine spatial detail while maintaining reliable subject separation, and this balance is achieved through a tightly integrated sequence of sensor readout, ISP processing, and AI inference.
Unlike conventional portrait modes that downsample to around 12MP, Pixel 10 Pro keeps much more native information in play, which directly affects edge accuracy around hair, fabric, and facial contours.
At the sensor level, the 50MP main camera with Octa PD provides dense phase-difference signals that act as physical depth hints. Google Research has previously shown that such disparity cues, even when noisy, significantly stabilize monocular depth estimation when fused with learning-based models.
These signals are passed to the custom ISP, where remosaic processing reconstructs a high-resolution Bayer image without aggressive pixel binning.
The next stage is where the pipeline differentiates itself. Instead of running segmentation only on a heavily reduced image, the ISP and Tensor G5 TPU cooperate to keep depth inference aligned with near–full-resolution data.
According to Google’s published work on on-device ML optimization, guided upsampling techniques allow coarse depth predictions to be refined using high-frequency image gradients.
| Pipeline Stage | Primary Input | Impact on Portrait Quality |
|---|---|---|
| Remosaic & HDR+ | 50MP RAW frames | Preserves texture and tonal micro-contrast |
| Depth Estimation | AI model + PD disparity | Improves boundary stability and scale accuracy |
| Edge-Aware Rendering | High-res depth map | Reduces cutout and halo artifacts |
The depth model itself resembles the “Depth Pro” class of architectures discussed in recent academic literature. These models emphasize sharp monocular depth with metric consistency, enabling smoother depth roll-off rather than abrupt blur transitions.
Researchers reporting on Depth Pro note inference times below one second on standard hardware, a requirement that aligns with Pixel 10 Pro’s real-time shooting experience.
Finally, the rendering stage applies a blur kernel whose strength varies continuously with estimated distance.
Because this calculation is driven by a higher-resolution depth map, background blur respects fine gaps, such as between strands of hair, more convincingly than earlier Pixels.
In practical use, reviewers and early users have observed that switching to 50MP portrait mode visibly improves segmentation fidelity. This outcome supports a core principle of computational photography long advocated by Google engineers: better input data reduces the burden on AI correction.
The 50MP portrait pipeline therefore represents not just a resolution upgrade, but a structural rethink of how depth, detail, and realism are computed together.
Edge Processing in Practice: Hair, Glasses, and Transparent Objects
Edge processing reaches its real test not on solid silhouettes, but around hair strands, eyewear, and transparent objects where foreground and background pixels blend together. In portrait photography, these regions expose whether depth estimation is merely plausible or genuinely precise. **Pixel 10 Pro’s approach emphasizes probabilistic boundaries rather than hard cutouts**, aiming for visual continuity even when depth confidence is low.
According to Google Research on depth prediction and segmentation, mixed pixels around hair are treated as continuous depth values instead of binary masks. This explains why individual flyaway hairs are often preserved at 50MP resolution, yet slightly softened at their edges. The system deliberately trades absolute sharpness for stability, reducing the risk of harsh clipping that would otherwise break realism.
| Object Type | Primary Challenge | Observed Processing Behavior |
|---|---|---|
| Hair | Sub-pixel thickness, partial transparency | Soft depth gradients to avoid cutout artifacts |
| Glasses | Reflection plus physical frame | Frames prioritized, lenses treated as depth-ambiguous |
| Glass objects | Refraction without texture | Edges partially merged with background |
Eyeglasses illustrate a deeper paradox. Frames are solid and usually segmented correctly, but lenses reflect background elements that confuse monocular depth models. Reports from user testing communities show that thin metal or rimless glasses may blur into the background, not due to lack of resolution, but because the AI cannot assign a stable depth plane to reflections. **This is a limitation shared across the industry**, including devices with dedicated depth sensors.
Transparent objects such as glassware remain the most difficult case. Because training data is heavily biased toward human subjects, depth models struggle with objects defined mainly by refraction. Google’s own community forums acknowledge lingering mist-like edges around glass contours. The choice to err on the side of softness reflects a design philosophy: it is visually safer to under-separate than to introduce physically impossible edges that immediately signal computational manipulation.
When AI Gets It Wrong: Depth Errors and Visual Artifacts
Even with the Pixel 10 Pro’s significantly improved depth estimation pipeline, there are moments when AI portrait processing does get it wrong, and these failures are especially visible to gadget enthusiasts who scrutinize images at the pixel level.
Depth errors and visual artifacts tend to emerge not in ideal conditions, but in scenes that challenge the assumptions of AI models. According to Google Research, modern monocular depth models excel at statistically common patterns, yet they still struggle when physical optics and visual semantics conflict.
One of the most common issues is incorrect depth ordering. In real-world samples, flat surfaces such as walls or pavements can show abrupt changes in blur strength, creating what reviewers often describe as depth cliffs. This happens when the estimated depth map loses continuity, even though the physical scene is smooth.
| Error Type | Typical Scene | Visible Result |
|---|---|---|
| Depth discontinuity | Walls, floors, skies | Sudden blur jumps |
| Boundary ambiguity | Hair, fur, foliage | Halo or misty edges |
| Transparency confusion | Glasses, glassware | Partial blur or cutout |
Hair remains the most demanding test. Although the 50MP portrait mode improves fine segmentation, complex backgrounds such as leaves or fences still trigger conservative smoothing. This safety-first behavior reduces harsh cutouts, but it can introduce a soft glow around the subject’s head. DxOMark reviewers have noted that this halo effect is more noticeable in backlit scenes, where highlights wash out depth cues.
Transparent and reflective objects expose a different weakness. Glasses illustrate a logical paradox for AI: the frame is solid, the lens is transparent, and reflections belong neither fully to subject nor background. User reports on Pixel forums show that thin metal frames or rimless glasses may be blurred into the background, while reflections are sometimes misclassified as background detail.
Polarized sunglasses add another layer of complexity. Multiple community tests indicate rainbow-like color artifacts or unexpected darkening on lenses. Imaging researchers attribute this to polarization mismatches between sensor filters and reflected light, which downstream AI tone mapping cannot fully reconcile.
These errors highlight an important limitation. AI-generated depth maps are predictions, not measurements. Unlike LiDAR-assisted systems, the Pixel 10 Pro relies heavily on learned inference combined with phase-detection hints. When visual cues contradict training data, the model produces a plausible but physically incorrect solution.
From a visual perspective, this sometimes leads to a cutout effect, where the subject appears pasted onto the background. Tech reviewers comparing Pixel and iPhone portrait shots often point out that Pixel images look more dramatic, but also more prone to artificial separation when depth estimation overshoots.
For enthusiasts, these artifacts are not deal-breakers, but they are instructive. They reveal where computational photography still diverges from optical reality, and they remind us that even state-of-the-art AI remains bounded by the data and assumptions it was trained on.
In short, the Pixel 10 Pro shows remarkable progress, yet its occasional depth errors serve as a clear window into the current limits of AI-driven vision.
Pixel 10 Pro vs iPhone 17 Pro vs Galaxy S25 Ultra
When comparing Pixel 10 Pro, iPhone 17 Pro, and Galaxy S25 Ultra, the most meaningful differences do not appear in headline specs, but in how each company defines a “good portrait.” Each model represents a distinct philosophy of computational photography, and understanding these differences helps readers choose a device that aligns with their own shooting style.
At a high level, Pixel prioritizes AI-driven subject separation, iPhone emphasizes optical realism, and Galaxy focuses on visual clarity and sharpness. This contrast becomes especially visible in edge handling, depth continuity, and consistency between preview and final output.
| Model | Depth Source | Portrait Character | Typical Strength |
|---|---|---|---|
| Pixel 10 Pro | AI depth + phase-detection hints | Subject-forward, dramatic | Hair detail, 50MP portraits |
| iPhone 17 Pro | LiDAR + multi-frame analysis | Natural, lens-like | Smooth depth roll-off |
| Galaxy S25 Ultra | AI edge detection | Sharp, high-contrast | Crisp outlines, zoom portraits |
Pixel 10 Pro stands out by fully leveraging Tensor G5 and high-resolution data. Google’s approach relies on dense AI segmentation combined with physical disparity information from Octa PD and Quad PD sensors. According to analyses referencing Google Research and DxOMark, this hybrid method allows Pixel to preserve extremely fine structures such as loose hair strands and fabric edges in 50MP portrait mode. As a result, portraits often appear striking and three-dimensional, which many users describe as visually impactful.
However, this strength also introduces trade-offs. Because Pixel aggressively separates subject and background, minor depth estimation errors can manifest as haloing or slightly misty edges, particularly in backlit scenes. The portrait looks impressive at first glance, but careful viewers may notice that the depth map is sometimes “too confident.”
iPhone 17 Pro takes a contrasting route. Apple’s continued use of LiDAR provides an explicit depth reference that reduces ambiguity at boundaries. Independent reviews from Tech Advisor and TechRadar note that iPhone portraits maintain smoother transitions between focus planes, especially around glasses, shoulders, and overlapping subjects. The blur falloff behaves closer to a real lens, with fewer abrupt changes in bokeh intensity.
This realism comes at a cost. Fine details such as flyaway hair are sometimes simplified, and overall sharpness in static portraits can appear lower than Pixel’s 50MP output. That said, the consistency between what users see in the viewfinder and the final image remains a major advantage, particularly for users who value predictability.
Galaxy S25 Ultra positions itself differently again. Samsung’s portrait processing emphasizes clarity and edge contrast, producing images that look crisp even on small screens. Community comparisons and Samsung forum discussions indicate that Galaxy excels at telephoto portraits, where subject isolation remains strong at longer focal lengths. This makes it appealing for users who frequently shoot from a distance.
On the other hand, the same sharpening can lead to unnatural skin texture and slightly jagged edges around hair. In portraits of people, Samsung’s processing may appear less forgiving, with smoothing applied unevenly depending on lighting and subject distance.
From an experiential perspective, the three devices also diverge in how “finished” a portrait feels straight out of the camera. Pixel photos tend to look social-media ready, with bold separation and strong presence. iPhone images feel subdued but refined, closer to traditional photography. Galaxy shots are immediately sharp and eye-catching, though sometimes less subtle.
In summary, Pixel 10 Pro rewards users who enjoy AI-driven expressiveness and maximum detail, iPhone 17 Pro suits those who value natural depth and reliability, and Galaxy S25 Ultra appeals to users who prefer clarity and reach. Understanding these underlying differences makes the comparison far more meaningful than specs alone.
Portrait Video, Stabilization, and the Limits of On-Device AI
Portrait video is where the strengths and weaknesses of on-device AI become most visible, and the Pixel 10 Pro offers a particularly instructive case. While its still-image portrait mode benefits from high-resolution depth maps and refined edge handling, translating those gains into moving images introduces a different class of constraints. In video, depth estimation, stabilization, and temporal consistency must all work in lockstep, and even small mismatches can be perceived immediately by the viewer.
At the core of the challenge is stabilization. The Pixel 10 Pro combines optical image stabilization with electronic image stabilization, a hybrid approach that is common across flagship smartphones. However, user reports and technical analyses indicate that, especially when using the telephoto lens, the interaction between these two systems is not always harmonious. Irregular micro-jumps and sudden frame corrections have been observed, which are subtle in standard video but amplified in portrait video where background blur magnifies motion errors.
From a technical perspective, electronic stabilization relies on frame-to-frame motion vectors, while optical stabilization physically shifts lens elements. If the AI model interprets OIS-induced movement as subject motion rather than camera shake, it may apply counter-corrections that overshoot. According to evaluations discussed by DxOMark and corroborated by independent reviewers, this misinterpretation leads to temporal instability in the depth map, where the perceived distance of the subject subtly oscillates across frames.
| Component | Primary Role | Impact on Portrait Video |
|---|---|---|
| OIS | Physical shake reduction | Stabilizes optics but introduces non-linear motion |
| EIS | Digital frame alignment | Can cause jitter when misaligned with OIS |
| On-device depth AI | Per-frame depth inference | Prone to flicker under unstable input |
The limitations here are not purely computational power issues. Tensor G5 is capable of running advanced depth models in real time, but video imposes strict latency budgets. Unlike still images, the system cannot afford multi-pass refinement or heavy temporal smoothing without introducing lag. Research from Google and other academic sources has shown that monocular depth models perform best with stable inputs; once rapid micro-movements are introduced, the AI must choose between responsiveness and consistency, and the Pixel 10 Pro often prioritizes responsiveness.
Google’s answer to this dilemma is Video Boost, a cloud-based pipeline that reprocesses footage with more robust stabilization and depth refinement. Expert commentary from imaging specialists notes that this approach produces visibly cleaner portrait video, with smoother background blur and more stable edges. However, it also highlights the current ceiling of on-device AI. When high-quality results depend on off-device computation, it becomes clear that real-time, fully local portrait video remains an unsolved problem.
In practical use, this means the Pixel 10 Pro delivers impressive portrait videos under controlled motion and wide-angle conditions, but struggles as focal length increases or camera movement becomes complex. These behaviors underscore a broader industry reality: on-device AI has reached a remarkable level of sophistication, yet video portraiture still exposes the fine boundary between what can be inferred instantly and what still requires time, context, and heavier computation.
参考文献
- Google Store:How Google Tensor Helps Google Pixel Phones Do More
- Google Blog:5 reasons why Google Tensor G5 is a game-changer for Pixel
- Android Authority:Exclusive: How Google built the Pixel 10’s Tensor G5 without Samsung’s help
- DxOMark:Google Pixel 10 Pro XL Camera Test
- Learn OpenCV:Depth Pro Explained: Sharp, Fast Monocular Metric Depth Estimation
- arXiv:Depth Pro: Sharp Monocular Metric Depth in Less Than a Second