
Artificial intelligence is no longer confined to massive cloud data centers. From smartphones to AI PCs, powerful models now run directly on personal devices, transforming how we interact with technology every day.
At the same time, concerns about surveillance, data harvesting, and invisible tracking have reached a tipping point. Many users love AI-powered convenience, yet hesitate to trust where their most personal data actually goes.
This article explores how on-device AI is reshaping privacy, security architecture, and digital ownership. By examining real-world implementations from Apple, Google, Microsoft, and Samsung, along with cutting-edge research on federated learning and side-channel attacks, you will gain a clear, evidence-based understanding of where AI security is heading—and what it means for your next gadget purchase.
- Why the AI Paradigm Is Shifting from Cloud to Device
- Latency, Cost, and Privacy: The Structural Limits of Cloud-Only AI
- The Rise of NPUs: Why 40 TOPS Became the New Performance Benchmark
- Small Language Models, Quantization, and the Engineering of Efficient Intelligence
- Apple Intelligence and Private Cloud Compute: Verifiable Transparency in Action
- Android’s AICore and Private Compute Core: Sandboxing AI at the OS Level
- Microsoft Recall and Copilot+ PCs: Lessons from a Security Redesign
- Samsung Knox Matrix and Knox Vault: Ecosystem-Level Defense with Hardware Isolation
- Federated Learning and Differential Privacy: Training AI Without Collecting Raw Data
- Emerging Threats: NPU Side-Channel Attacks, Model Extraction, and Prompt Injection
- Consumer Trust, Digital Ethics, and the Competitive Value of Privacy
- 参考文献
Why the AI Paradigm Is Shifting from Cloud to Device
From 2024 to 2025, the center of gravity in AI computing is clearly moving from cloud data centers back to personal devices. What began as a cloud-dominated era powered by massive GPU clusters is now evolving into a distributed model where smartphones, PCs, and edge devices handle intelligence locally.
This shift is not ideological; it is structural. As generative AI becomes embedded into operating systems and daily workflows, the limitations of a purely cloud-centric model are becoming impossible to ignore.
The migration from cloud to device is driven by three structural pressures: latency, cost scalability, and data sovereignty.
First, latency. Real-time translation, AR navigation, instant photo enhancement, and always-on AI assistants cannot tolerate hundreds of milliseconds of round-trip network delay. Human perception is sensitive to even slight lag. If AI is expected to operate at the speed of thought, inference must occur locally, without waiting for a server response.
Second, economic scalability. Even a 7-billion-parameter model incurs non-trivial inference costs when deployed through cloud APIs. If billions of users interact with AI hundreds of times per day, server infrastructure and bandwidth costs scale exponentially. As industry discussions around on-device LLM deployment highlight, distributing inference workloads to user devices transforms AI from a centralized expense into a decentralized computation layer.
| Dimension | Cloud-Centric AI | On-Device AI |
|---|---|---|
| Latency | Network-dependent | Near-instant local inference |
| Operational Cost | Centralized server burden | Distributed across edge devices |
| Data Handling | Remote transmission required | Processed within user device |
Third, and most critically, privacy. Cloud AI fundamentally requires data transmission to external servers. Whether the data involves medical records, financial information, personal photos, or corporate documents, it temporarily leaves the user’s direct control. According to analyses from Stanford HAI and public sector privacy authorities, this architectural reality introduces systemic risks: data breaches, secondary data use for model training, and potential governmental access.
On-device AI reframes privacy not as a policy promise, but as an architectural constraint. If data never leaves the device, many categories of remote breach simply become irrelevant. This is the essence of data sovereignty—the ability of individuals to retain physical and logical control over their information.
Importantly, this does not mean the cloud disappears. Rather, intelligence becomes tiered. Devices handle sensitive, latency-critical tasks locally, while only complex or non-sensitive workloads escalate to remote infrastructure. As recent industry commentary notes, this hybrid model reflects a maturation of AI architecture rather than a rejection of cloud computing.
The paradigm shift is therefore not about performance alone. It is about redefining where trust resides. During the first wave of AI, trust was placed in hyperscale providers. In the emerging wave, trust is increasingly anchored in silicon—inside the chips and secure enclaves of personal devices.
For gadget enthusiasts and technology professionals, this transition marks a deeper transformation. AI is no longer just a service you query; it is becoming an ambient capability embedded in your device. And when intelligence lives in your pocket instead of a distant data center, the balance of power between user and platform begins to change.
Latency, Cost, and Privacy: The Structural Limits of Cloud-Only AI
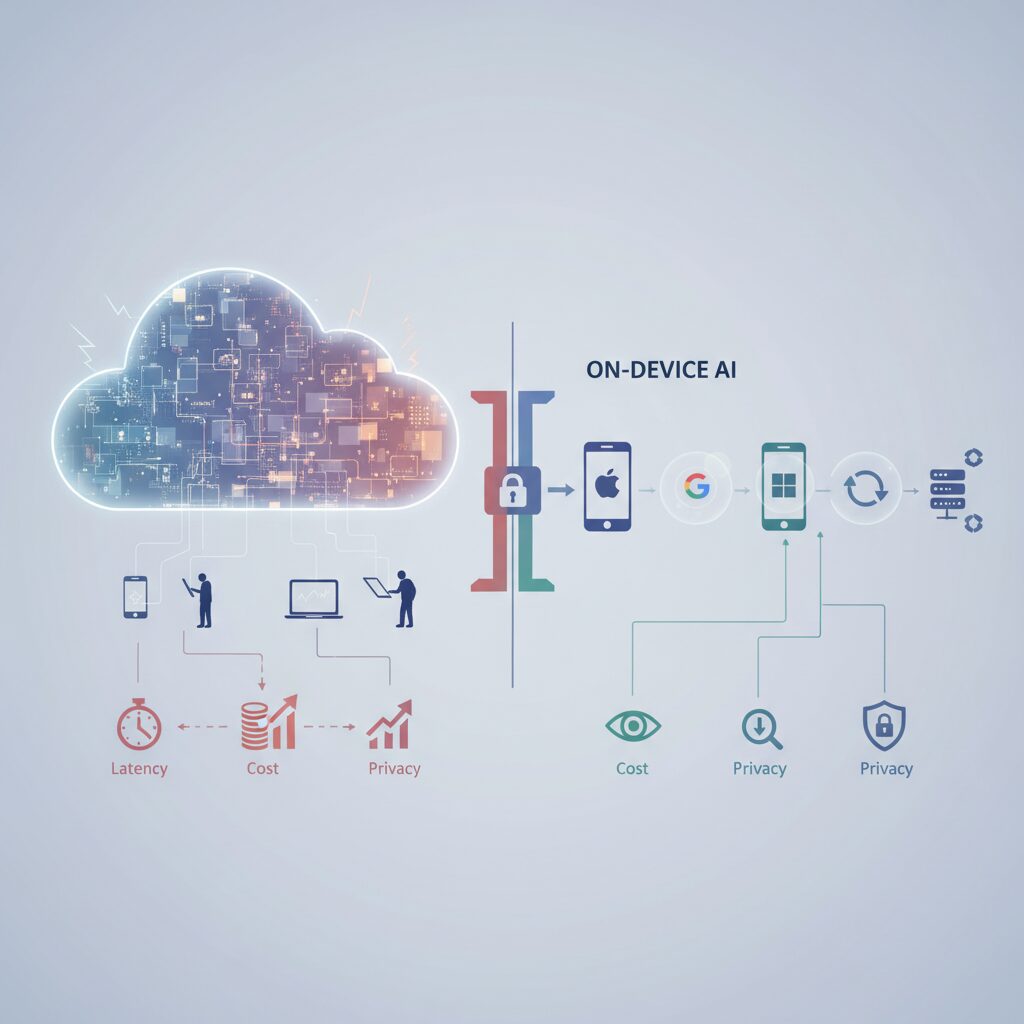
Cloud-only AI has powered the generative boom, but its structural limits are becoming impossible to ignore. As AI shifts from occasional queries to always-on assistants, three constraints repeatedly surface: latency, cost, and privacy.
These are not minor trade-offs. They are architectural bottlenecks that directly shape user experience, business sustainability, and trust.
Latency: When Milliseconds Break the Illusion
Human perception is highly sensitive to delay. In real-time translation, AR navigation, or live camera enhancement, even a few hundred milliseconds of round-trip network latency can disrupt immersion.
According to industry analyses referenced by HP Tech Takes and Microsoft’s enterprise discussions, cloud inference requires data to travel from device to server and back, introducing unavoidable network variability. Even with fast 5G, congestion and routing add unpredictability.
If AI is to operate at the speed of thought, removing the network round trip becomes essential. This is especially critical for OS-level features that must feel instantaneous rather than transactional.
| Factor | Cloud-Only AI | User Impact |
|---|---|---|
| Processing Location | Remote data center | Dependent on network quality |
| Typical Delay Source | Upload + inference + download | Lag in real-time tasks |
| Failure Mode | Network outage | Feature becomes unavailable |
Cost: The Economics of Scale
Large language models require significant GPU infrastructure. Even a 7B-parameter model running inference at scale consumes non-trivial compute resources. As discussed in product architecture analyses on Medium and Microsoft community channels, per-query cost does not disappear simply because the interface feels lightweight.
Now imagine billions of users making hundreds of AI interactions per day. Server-side inference at that scale implies massive capital expenditure in GPUs, energy, cooling, and bandwidth.
Cloud-only AI centralizes intelligence—but also centralizes cost. That concentration creates pricing pressure, API dependency risks, and long-term sustainability questions for product teams.
Bandwidth is another hidden variable. Continuous uploads of voice, images, and contextual data strain telecom infrastructure, especially in emerging markets where connectivity is uneven.
Privacy: Structural Exposure by Design
The most profound limitation is architectural. Cloud AI, by definition, requires user data to leave the device. Whether it is medical information, financial documents, or private conversations, the processing pipeline involves transmission to remote servers.
Stanford HAI and public policy bodies such as the Office of the Victorian Information Commissioner have repeatedly highlighted that centralization increases aggregation risk. Even with encryption in transit and at rest, data concentration creates attractive targets for attackers.
The issue is not only breach risk, but secondary use and governance. Users must trust that providers will not reuse prompts for model training, profiling, or analytics beyond their expectations.
Enterprise adoption illustrates this tension clearly. As Microsoft’s enterprise security discussions note, organizations hesitate to expose proprietary documents or trade secrets to external APIs without strict guarantees.
Latency limits responsiveness, cost limits scalability, and privacy limits trust. Together, they define the structural ceiling of cloud-only AI.
These constraints do not imply that cloud AI is obsolete. Rather, they reveal why relying exclusively on centralized inference is increasingly misaligned with always-on, deeply personal computing.
As AI becomes embedded into daily workflows instead of occasional prompts, architectures that ignore these three structural pressures will struggle to deliver both performance and credibility.
The Rise of NPUs: Why 40 TOPS Became the New Performance Benchmark
The shift toward on-device AI has elevated one component from a niche accelerator to a strategic centerpiece: the Neural Processing Unit. In 2024, the conversation moved beyond whether a device had an NPU to how powerful it was. The number that crystallized this shift was 40 TOPS—trillions of operations per second.
This figure did not emerge randomly. It became a practical threshold as operating systems began embedding generative AI features directly into core workflows. Microsoft, for example, defined its Copilot+ PC category around a minimum of 40 TOPS of NPU performance, signaling that AI was no longer an app-level add-on but an OS-level expectation.
Why 40 TOPS Matters
| Metric | What It Represents | Why It Matters |
|---|---|---|
| TOPS | Trillions of operations per second | Raw AI inference throughput |
| 40 TOPS | Baseline for AI PCs | Enables real-time, always-on AI features |
| Performance per Watt | Efficiency under load | Sustains battery life during continuous inference |
According to technical explanations from HP and Microsoft, modern AI assistants are not sporadic workloads. They analyze context, summarize documents, enhance images, and process voice locally—often in the background. Below a certain performance floor, latency increases and battery drain becomes unacceptable.
The 40 TOPS benchmark reflects the computational demand of running quantized small language models, real-time translation, and multimodal processing without relying on the cloud. It marks the point where AI transitions from reactive to proactive.
Equally important is efficiency. As industry analyses emphasize, NPUs are optimized for low-precision operations such as INT8, which dominate inference tasks. Compared to GPUs, NPUs deliver dramatically higher performance per watt for matrix multiplications, making continuous AI feasible on thin laptops and smartphones.
The competitive response was immediate. Qualcomm’s Snapdragon X series, AMD’s Ryzen AI 300, and Intel’s Core Ultra architectures integrated increasingly powerful NPUs to meet or exceed this requirement. Apple’s Neural Engine evolution follows a similar trajectory, focusing on tightly coupled hardware–software optimization rather than raw headline figures.
From a market perspective, the emergence of a clear numeric benchmark simplifies purchasing decisions. Just as “Retina” once defined display clarity and “5G” defined connectivity generation, 40 TOPS now signals AI readiness. For enthusiasts and professionals alike, it provides a shorthand for future-proofing.
More subtly, this benchmark reflects a deeper architectural shift. AI is no longer burst compute handled in the cloud. It is ambient, persistent, and privacy-sensitive. Sustaining that reality requires guaranteed local inference capacity. The rise of NPUs—and the standardization around 40 TOPS—formalizes that new baseline for personal computing.
Small Language Models, Quantization, and the Engineering of Efficient Intelligence

As AI shifts from massive cloud models to devices in your pocket, the spotlight moves to Small Language Models (SLMs) and quantization. Instead of asking how large a model can become, engineers now ask how small it can be while remaining useful.
According to recent surveys on on-device language models published on arXiv, task-optimized smaller models often deliver comparable accuracy within constrained domains. This design philosophy is central to efficient intelligence: specialization over scale.
SLMs such as Gemini Nano or Apple’s on-device models, reportedly around a few billion parameters, are engineered to run within limited RAM budgets like 8GB or 12GB. Instead of general world knowledge, they prioritize tightly scoped tasks such as summarization, smart replies, or local rewriting.
This shift changes the optimization target. In cloud AI, latency and cost are absorbed by data centers. On-device, every byte of memory and every watt of battery matters.
| Aspect | Large Cloud LLM | On-Device SLM |
|---|---|---|
| Parameter Scale | Hundreds of billions+ | Billions or fewer |
| Primary Optimization | Raw capability | Efficiency & latency |
| Deployment | Data centers | Smartphones / PCs |
The second pillar of efficient intelligence is quantization. Traditionally, model weights are stored in 32-bit floating point (FP32). Quantization reduces this precision to 16-bit, 8-bit, or even 4-bit representations.
Research cited in on-device AI engineering discussions shows that well-calibrated INT8 and INT4 quantization can reduce memory usage to a fraction—sometimes one quarter or less—while maintaining task-level quality that remains practically indistinguishable to users.
This reduction has cascading benefits. Smaller weights mean lower memory bandwidth pressure, faster inference, and better thermal stability. On mobile devices, that directly translates into sustained performance without aggressive throttling.
Quantization is not a naive truncation process. Advanced techniques such as per-channel scaling and post-training calibration help preserve distributional characteristics of weights. The result is a model that behaves similarly to its higher-precision counterpart, but fits into dramatically smaller hardware envelopes.
Another critical technique is model distillation. A large “teacher” model transfers knowledge to a smaller “student” model, compressing reasoning patterns rather than copying parameters. Microsoft and other researchers have noted that distilled models fine-tuned for specific domains can outperform larger general-purpose systems in narrowly defined workflows.
For gadget enthusiasts, this engineering reality explains why a device with a powerful NPU and a carefully quantized SLM can feel instantly responsive. There is no network round trip, no queue in a remote GPU cluster—just optimized local inference tuned to hardware.
The future of intelligent devices will not be defined by parameter counts alone, but by how intelligently those parameters are engineered. In this era, elegance lies in constraint, and true innovation emerges from making intelligence smaller, faster, and more efficient without sacrificing real-world utility.
Apple Intelligence and Private Cloud Compute: Verifiable Transparency in Action
Apple Intelligence is built on a clear principle: process as much as possible on the device, and only use the cloud when absolutely necessary. For everyday tasks such as notification summaries or writing assistance, the approximately 3‑billion‑parameter on‑device model runs locally on iPhone, iPad, and Mac.
When a request requires more computational power, Apple routes it to Private Cloud Compute (PCC). What makes this different is not the hybrid model itself, but how the cloud has been redesigned to mirror the privacy guarantees of the device.
Private Cloud Compute is engineered so that even Apple cannot access your data in a readable form. This is enforced technically, not promised contractually.
PCC servers run on Apple-designed silicon, extending hardware security concepts such as Secure Boot and Secure Enclave into the data center. According to Apple’s security documentation, every layer of the software stack is cryptographically signed and verified at boot time, establishing a hardware root of trust.
This means that if the server software is modified or tampered with, the system will refuse to run. The trust chain begins at the silicon level and extends upward, reducing the risk of firmware backdoors or unauthorized code execution.
| Layer | Traditional Cloud | Private Cloud Compute |
|---|---|---|
| Hardware | Commodity server CPUs | Apple silicon with hardware root of trust |
| Software Integrity | Provider-controlled validation | Cryptographically verifiable boot chain |
| Data Retention | Logs and storage may persist | Stateless, memory-only processing |
Another radical design choice is stateless computation. User data sent to PCC exists only in volatile memory during processing and is deleted immediately after a response is generated. It is not written to persistent storage.
Moreover, privileged remote access mechanisms are intentionally removed. Even Apple engineers cannot log into a live PCC node to inspect user requests. As security researchers have noted, this shifts the model from policy-based trust to architecture-enforced trust.
The most distinctive element is what Apple calls “verifiable transparency.” Portions of the PCC software stack are made available through a Virtual Research Environment, enabling independent security researchers to inspect the code for vulnerabilities.
When your device connects to PCC, it cryptographically verifies that the server is running the same publicly reviewed software image. If the signature does not match, the request is blocked. This creates a measurable, testable trust relationship between device and cloud.
Apple has also integrated PCC into its security research program, offering significant bug bounty rewards for validated vulnerabilities. By inviting external scrutiny, the company aligns with the broader academic consensus, echoed by institutions such as Stanford HAI, that AI privacy must be auditable rather than assumed.
In practice, Private Cloud Compute transforms the cloud from a black box into a cryptographically provable extension of the device. For users who demand both generative AI power and strict data sovereignty, this architecture represents a new benchmark in transparent AI infrastructure.
Android’s AICore and Private Compute Core: Sandboxing AI at the OS Level
In the Android ecosystem, AI is not treated as just another app feature but as a system-level capability. To make on-device AI both powerful and safe, Google introduced two tightly connected pillars: AICore and Private Compute Core (PCC). Together, they sandbox AI directly at the OS layer, not merely at the application layer.
This architectural decision reflects a clear philosophy. If AI handles voice, screen content, and personal text, then isolation must be enforced by the operating system itself, where trust boundaries are strongest.
AICore: Centralized Model Management Inside Android
AICore functions as a system service that manages on-device models such as Gemini Nano. Instead of each app bundling its own large language model, apps call standardized APIs exposed by AICore.
This separation creates a strict boundary between application logic and model execution. According to the Android Developers Blog, apps submit prompts while inference runs in an isolated environment controlled by the OS.
| Layer | Role | Security Benefit |
|---|---|---|
| Application | Sends prompt via API | No direct model access |
| AICore | Runs inference | Process isolation |
| Model Storage | Managed by system | Prevents model extraction |
Because the model is abstracted away from apps, developers cannot directly read, copy, or tamper with it. This reduces intellectual property leakage and mitigates model extraction risks discussed in recent LLM security research.
Equally important, memory isolation ensures that one app’s inference request cannot be inspected by another process. The OS enforces separation at the process boundary, significantly reducing lateral data exposure.
Private Compute Core: An OS-Level AI Sandbox
While AICore manages models, Private Compute Core defines where sensitive AI processing can occur. PCC is a hardened sandbox within Android dedicated to handling data such as audio streams, screen text, and notification content.
As explained on Google’s Online Security Blog, services operating inside PCC are restricted from direct internet access. This design blocks accidental or malicious exfiltration of raw user data.
The network boundary is enforced structurally. PCC components cannot freely open sockets to external servers. Instead, any necessary communication—such as model updates—must pass through Private Compute Services, which filters identifiers and limits metadata exposure.
Even if an AI feature processes highly sensitive input, the architecture ensures that raw data remains confined within a network-isolated sandbox.
Another critical safeguard is zero-retention behavior. Inference contexts are not persistently stored across sessions unless explicitly required by the user. This minimizes residual data risk in case of compromise.
From a security engineering standpoint, Android’s approach acknowledges a key reality: on-device does not automatically mean secure. Malware running with user privileges could still attempt memory scraping or privilege escalation. By anchoring AI execution inside OS-enforced sandboxes, Google reduces the attack surface before it reaches application space.
For gadget enthusiasts and power users, this means the intelligence embedded in Android increasingly operates like a protected subsystem rather than a feature bolted onto apps. The operating system itself becomes the guardian of AI-driven data flows, redefining what “on-device privacy” truly means at scale.
Microsoft Recall and Copilot+ PCs: Lessons from a Security Redesign
When Microsoft unveiled Recall as a flagship feature of Copilot+ PCs, it promised something close to photographic memory for your computer. Every few seconds, the system captured snapshots of on-screen activity, indexed them with OCR and AI, and made your entire digital history searchable in natural language.
From a productivity standpoint, it was revolutionary. From a security standpoint, it immediately triggered alarms across the research community.
According to independent security analyses and early technical reviews, the initial preview implementation stored Recall data locally in a SQLite database that was not encrypted at rest. This meant that if malware gained user-level access, it could potentially extract months of sensitive activity in minutes.
| Phase | Design Characteristic | Security Implication |
|---|---|---|
| Initial Preview | Snapshots stored locally, insufficient protection | High risk if device compromised |
| Redesigned Recall | Encryption + biometric gate + secure enclave | Layered defense against malware access |
The backlash was swift. Security researchers demonstrated how infostealer malware could target Recall’s database. As Kaspersky’s official analysis noted, a feature designed for convenience could become a “treasure trove” for attackers if not properly isolated.
Microsoft responded not with incremental patches, but with a structural redesign. The updated architecture introduced mandatory opt-in activation, meaning Recall is disabled by default. Users must explicitly enable it during setup.
More importantly, access to Recall data now requires Windows Hello authentication. This just-in-time decryption model ensures that even if malware is running in the background, it cannot silently browse your activity history without biometric confirmation.
This shift marked a crucial lesson for on-device AI: local processing alone does not equal security.
The redesigned Recall also leverages Virtualization-Based Security (VBS) enclaves. Sensitive processing occurs inside an isolated memory region protected by the hypervisor, reducing exposure even if the main OS is compromised. Microsoft further integrates the Pluton security processor, which safeguards cryptographic keys at the silicon level.
In effect, Copilot+ PCs now treat AI memory as high-value cryptographic material rather than ordinary app data. That architectural mindset is the real transformation.
For gadget enthusiasts and power users, the Recall episode offers a broader insight: AI features that continuously observe user context must be designed under a zero-trust assumption. The operating system itself cannot be blindly trusted once malware enters the picture.
Microsoft’s course correction demonstrates an emerging industry standard. AI-powered operating systems must combine on-device inference, hardware-backed key protection, biometric proof of presence, and strict isolation boundaries.
The lesson is clear: in the age of ambient AI, security architecture must precede innovation—not follow public backlash.
Samsung Knox Matrix and Knox Vault: Ecosystem-Level Defense with Hardware Isolation
Samsung approaches on-device AI security from a broader perspective: not just protecting a single smartphone, but defending the entire device ecosystem as one unified trust domain. With Knox Matrix and Knox Vault, Samsung combines cross-device verification and hardware-level isolation to reduce both remote and physical attack surfaces.
According to Samsung’s official security documentation, this architecture is designed to ensure that even as Galaxy AI features expand, sensitive data remains under user control and cryptographically protected at every layer.
Knox Matrix: Blockchain-Based Mutual Trust
Knox Matrix connects Galaxy smartphones, tablets, wearables, TVs, and even home appliances into a private blockchain-based trust network. Instead of treating each device as an isolated endpoint, it enables them to verify one another’s integrity continuously.
This “mutual monitoring” model means that if one device shows signs of compromise—such as abnormal firmware signatures or system tampering—other trusted devices can flag it as untrustworthy and restrict interactions.
| Component | Security Role | Defense Focus |
|---|---|---|
| Private Blockchain | Device integrity verification | Cross-device authentication |
| Mutual Monitoring | Real-time trust evaluation | Compromised device isolation |
This ecosystem-level defense is particularly relevant in AI-powered homes, where smart refrigerators, TVs, and mobile devices share contextual data. As Samsung notes in its Knox Matrix briefings, stronger devices can effectively shield weaker IoT endpoints, reducing lateral movement risks inside the network.
Knox Vault: Hardware-Level Isolation
While Knox Matrix protects across devices, Knox Vault protects within the device itself. It is a physically isolated subsystem composed of a dedicated processor and secure memory, separated from the main application processor running Android.
Credentials such as PINs, passwords, biometric templates, and cryptographic keys are stored inside this secure enclave. Even if the operating system is compromised, direct access to Vault-stored secrets is blocked at the hardware level.
Samsung’s Knox whitepapers explain that the system can detect abnormal electrical or physical conditions and trigger protective responses, including secure data erasure. This is critical as smartphones increasingly function as digital identity hubs for payments, enterprise authentication, and AI-personalized services.
By combining blockchain-based ecosystem validation with hardware-enforced secret isolation, Samsung creates a layered model aligned with modern threat research highlighted by organizations such as NCC Group, which emphasizes hardware-rooted trust as essential for edge AI security.
For gadget enthusiasts evaluating AI-enabled devices, the takeaway is clear: security is no longer just about encryption in software, but about how deeply trust is embedded into silicon and extended across your entire device ecosystem. Knox Matrix and Knox Vault represent Samsung’s answer to that architectural challenge.
Federated Learning and Differential Privacy: Training AI Without Collecting Raw Data
Federated learning and differential privacy are redefining how AI models improve without centralizing personal data.
Instead of collecting raw user information in the cloud, these techniques allow models to learn from millions of devices while keeping sensitive data local.
The data stays on your device, but the intelligence still scales globally.
How Federated Learning Works in Practice
Traditional machine learning aggregates user data into centralized servers for training. Federated learning reverses this flow.
According to case studies published by Apple Machine Learning Research and LINE Yahoo’s privacy center, the global model is first distributed to user devices, where training occurs locally using on-device data.
Only model updates—such as gradient adjustments or weight deltas—are sent back to the server, not the underlying raw inputs.
| Stage | Traditional Training | Federated Learning |
|---|---|---|
| Data Location | Centralized server | User device |
| What Is Sent to Server | Raw user data | Model updates only |
| Privacy Risk | High if breached | Reduced by design |
A concrete example is LINE’s sticker recommendation feature. User interactions remain on the smartphone, while only aggregated learning signals are transmitted. Training occurs when the device is idle and charging, minimizing performance and battery impact.
This architecture distributes computation across millions of endpoints, dramatically lowering centralized data exposure.
Differential Privacy: Mathematical Protection Against Re-Identification
Federated learning alone is not sufficient. Researchers have demonstrated that model updates can sometimes be reverse-engineered to infer original data.
This is where differential privacy adds a crucial layer.
Statistical noise is deliberately injected into the updates before transmission.
Apple’s research on aggregate trend analysis explains that carefully calibrated noise ensures individual contributions cannot be isolated, while large-scale statistical patterns remain accurate.
When millions of noisy updates are averaged, the randomness cancels out at scale, preserving overall signal while obscuring personal traces.
This transforms privacy from a policy promise into a mathematically provable guarantee.
For gadget enthusiasts and AI power users, this architecture signals a deeper shift. Your device is no longer just a client—it becomes an active participant in global model improvement.
As Stanford HAI has emphasized in discussions on privacy in the AI era, scalable intelligence must coexist with strong data protection principles.
Federated learning combined with differential privacy demonstrates that high-performance AI does not require harvesting raw personal data, marking a foundational change in how next-generation AI systems are trained.
Emerging Threats: NPU Side-Channel Attacks, Model Extraction, and Prompt Injection
As on-device AI becomes more powerful, the threat landscape shifts from cloud breaches to attacks that target the device’s AI engine itself. Researchers are now focusing on how NPUs, compact language models, and autonomous agents can be exploited in ways that were irrelevant just a few years ago.
The paradox is clear: the closer AI moves to your data, the more attractive the device becomes as a high‑value target.
NPU Side-Channel Attacks: When Physics Betrays AI
Side-channel attacks do not break encryption directly. Instead, they observe physical signals such as power consumption, timing, or cache behavior to infer what is being processed internally. According to research from CISPA on the Collide+Power technique, even subtle power variations can reveal sensitive computation patterns on modern processors.
Recent academic work, including sNPU and NeuroPlug, shows that integrated NPUs may leak information through similar channels during neural network inference. Because matrix multiplications depend on input data values, power traces and memory access patterns can unintentionally encode fragments of user inputs, such as text embeddings or image features.
| Attack Vector | Observed Signal | Potential Exposure |
|---|---|---|
| Power Analysis | Voltage fluctuations | Inference inputs or model states |
| Cache Probing | Memory timing differences | Layer execution patterns |
| Thermal Monitoring | Heat distribution | Workload characteristics |
Mitigations such as constant-time execution or noise injection exist, but they reduce efficiency. This creates a structural tension between performance-per-watt optimization and side-channel resilience.
Model Extraction: Stealing the Brain
On-device deployment means the model file resides on user hardware. Surveys on model extraction attacks against large language models highlight two primary risks: direct reverse engineering of weights and query-based cloning through systematic probing.
In query-based extraction, an attacker sends carefully crafted inputs and records outputs to train a surrogate model that approximates the original. Over time, the intellectual property embedded in compressed or distilled models can be replicated with surprising fidelity.
More concerning is membership inference. As noted in recent safety analyses of LLMs, attackers may determine whether specific data points were included in training, potentially exposing personal information embedded in fine-tuned models.
Prompt Injection: When Instructions Turn Malicious
Prompt injection attacks exploit the interpretative nature of language models. Instead of attacking the model’s weights, adversaries manipulate its instructions. Research on mobile LLM agents demonstrates that hidden text embedded in webpages can override user intent.
For example, an AI agent asked to summarize a webpage may encounter invisible instructions telling it to exfiltrate stored contacts or authentication tokens. If the model has OS-level permissions, the boundary between text processing and system control collapses.
Defenses require strict capability scoping, input sanitization, and separation between reasoning modules and execution modules. The challenge is architectural, not merely algorithmic.
Emerging threats against NPUs and on-device models are not theoretical edge cases—they represent a new security frontier where hardware design, model governance, and OS isolation must converge.
As Stanford HAI has emphasized in broader AI privacy discussions, technical safeguards must evolve alongside deployment models. In the era of on-device AI, protecting data sovereignty demands defending not only storage and transmission, but also computation itself.
Consumer Trust, Digital Ethics, and the Competitive Value of Privacy
As AI capabilities move closer to the device, consumer trust becomes the ultimate battleground. For gadget enthusiasts who evaluate products not only by performance but by philosophy, privacy is no longer a feature checkbox. It is a signal of digital ethics and long-term brand credibility.
Recent research in Japan highlights this tension. According to NEC’s 2025 survey on AI-era consumer awareness, 75% of respondents have experienced personalized AI services, yet 66% describe them as “convenient but anxiety-inducing.” Even more striking, 82% report having felt some form of “insincere experience” in digital services, including opaque data sharing or manipulative design patterns.
| Indicator | Survey Result |
|---|---|
| Experience with AI personalization | 75% |
| Feel “convenient but anxious” | 66% |
| Experienced digital insincerity | 82% |
This data reveals a structural trust gap. Users embrace AI’s utility, yet they question the intentions and transparency of the companies behind it. In this environment, privacy architecture becomes a marketing differentiator as much as a technical safeguard.
Stanford HAI has argued that privacy in the AI era cannot rely solely on policy promises but must be embedded into system design. That perspective aligns with the growing demand for verifiable mechanisms such as on-device processing, federated learning, and mathematically provable approaches like differential privacy. When users understand that raw data never leaves their device, trust shifts from abstract policy to tangible architecture.
The Mitsubishi Research Institute has estimated that establishing trustworthy generative AI frameworks could generate trillions of yen in added economic value for Japan. The implication is clear: companies that institutionalize digital ethics are not sacrificing growth; they are unlocking it.
For hardware makers and platform vendors, this means reframing privacy from defensive messaging to proactive value creation. Transparent data flows, opt-in defaults, clear retention policies, and hardware-backed isolation mechanisms are not merely technical decisions. They communicate respect.
In highly informed gadget communities, purchasing decisions increasingly factor in how a device processes data, not just how fast it performs. A smartphone that explains where inference occurs and how data is encrypted sends a stronger brand signal than one that advertises only TOPS performance.
Digital ethics also influences ecosystem lock-in. When users believe a brand safeguards their data sovereignty, they are more willing to integrate additional devices, services, and subscriptions. Trust reduces friction. Friction reduction drives lifetime value.
Ultimately, competitive advantage in the AI era will not be secured by model size alone. It will be secured by credibility. Companies that align technical architecture with transparent communication and user control will define the next generation of premium brands. In a market saturated with intelligent features, ethical design becomes the rarest innovation.
参考文献
- Apple Security Blog:Private Cloud Compute: A new frontier for AI privacy in the cloud
- Google Online Security Blog:Trust in transparency: Private Compute Core
- Windows Experience Blog:Update on Recall security and privacy architecture
- Samsung Newsroom:Knox Matrix: 10 Years of Samsung Knox Security and Samsung’s Vision for a Safer Future
- Android Developers Blog:An introduction to privacy and safety for Gemini Nano
- Kaspersky Official Blog:Microsoft Copilot+ Recall: who should disable it, and how
- Apple Machine Learning Research:Understanding Aggregate Trends for Apple Intelligence Using Differential Privacy